

Mastering data classification is the cornerstone of modern cybersecurity, enabling organizations to identify, categorize, and protect their most valuable information assets in an increasingly complex digital landscape.
This guide explores the essential principles of data classification, covering its core definitions, business benefits, and implementation strategies. From risk management to regulatory compliance, learn how to categorize information effectively to enhance security and operational efficiency.
Why Data Classification Matters in Today’s Digital World
Data classification is the systematic process of labeling data to make it easily searchable and traceable. In the context of security, it involves assessing the sensitivity of information to determine the appropriate level of control. Whether you are a small business owner focusing on automation for small businesses or a corporate security professional, understanding these principles is necessary to protect your funds in a rapidly evolving ecosystem.
The Strategic Importance of Categorization
- Risk Management: Identifying which assets require the highest levels of protection allows for better risk management.
- Resource Allocation: Directing security budgets and personnel where they are most needed.
- Compliance: Meeting requirements for regulations such as GDPR, HIPAA, or CCPA.
- Access Control: Determining who should have access to specific information, often integrated with automated CRM data entry systems.
- Data Lifecycle Management: Guiding retention, archiving, and deletion policies.
Core Concepts and Definitions
At its essence, data classification organizes information into categories for easier retrieval. In information security, this means categorizing data based on its sensitivity level, value to the organization, and regulatory requirements.
The foundation of an effective framework lies in the realization that a “one size fits all” security approach is both expensive and inefficient. According to Backlinko, understanding user intent and data context is key to any digital strategy, and the same applies to how we label internal information.
The Business Benefits of Implementing Data Classification
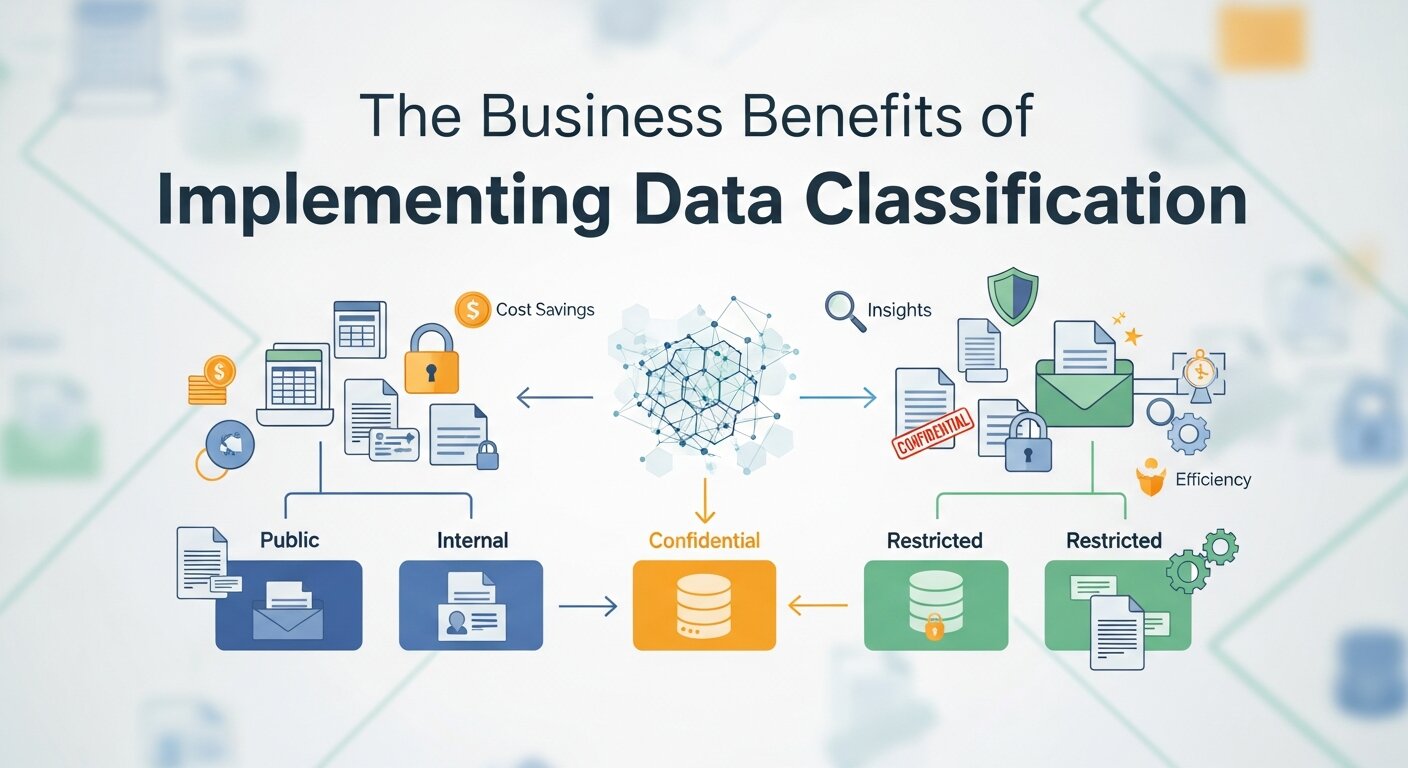
Organizations that invest in comprehensive data classification strategies realize benefits that extend far beyond basic security. These advantages directly impact the bottom line and operational efficiency.
1. Enhanced Security Posture
With properly classified data, security teams can implement targeted controls. This ensures that “Restricted” data receives encryption and multi-factor authentication, while “Public” data remains accessible, reducing the overall risk of a breach.
2. Regulatory Compliance
Many industries face strict laws regarding data handling. Data classification simplifies compliance by clearly identifying which datasets fall under specific frameworks like PCI DSS. This systematic approach reduces audit costs and minimizes the risk of heavy penalties.
3. Optimized Storage Costs
Not all data requires expensive, high-availability storage. Through effective classification, organizations can use tiered storage—placing archival data on cost-effective platforms while reserving premium storage for active, vital information. Research by Gartner suggests that organizations can reduce storage costs by up to 30% through proper lifecycle management.
4. Improved Data Discovery and Access
When information is labeled correctly, employees spend less time searching and more time performing. This is especially true when using Data Entry Automation Software or mastering automation in excel data entry, where classified fields allow for faster sorting and reporting.
| Data Category | Sensitivity Level | Access Level | Example |
| Public | Low | Everyone | Marketing Brochures |
| Internal | Medium | Employees Only | Office Policies |
| Confidential | High | Management/Specific Depts | Customer Lists |
| Restricted | Critical | Executive/Legal | Trade Secrets/SSNs |
Types of Data Classification: Methods and Approaches
Organizations typically employ a mix of these three primary methods to ensure comprehensive coverage:
Content-Based Classification
This approach inspects the actual content within files. For example, textual data entry systems can be programmed to recognize patterns like credit card numbers or social security numbers. Advanced artificial intelligence in business now uses machine learning to recognize sensitive “context” even in unstructured documents.
Context-Based Classification
This looks at metadata—the “who, what, where, and when” of the data.
- Who created the data (e.g., the CFO)?
- Which department owns it (e.g., Legal)?
- Where is it stored (e.g., a secure Hubspot data entry portal)?
User-Defined Classification
This relies on the knowledge of the data creator. When an employee saves a document, they manually select a tag (e.g., “Confidential”). While this leverages human insight, it requires significant training and brand voice strategy alignment to ensure consistency.
How to Implement an Effective Data Classification Framework

1. Define Classification Objectives
Are you trying to meet a specific marketing analytics data standard, or are you focused on protecting intellectual property? Clear goals prevent “scope creep” and keep the project manageable.
2. Establish Classification Policies
Develop a policy that defines your categories. This should be as clear as a brand strategy guide, ensuring every employee knows the difference between “Confidential” and “Restricted.”
3. Conduct Data Discovery and Inventory
You cannot protect what you don’t know you have. Use automated tools to scan your network, cloud storage, and SaaS development services to find “dark data.”
4. Implement Classification Tools
Select technology that integrates with your current workflow. For instance, if you use Hubspot data entry or automated data entry xero, choose tools that can read and apply tags within those ecosystems.
5. Train Employees and Build Awareness
Just as a content marketing plan requires team buy-in, so does data security. Use webinars for education to teach staff how to handle sensitive information. Including a webinar in resume skills is becoming common for IT professionals who manage these training sessions.
The Role of Automation and AI in Data Management
As we move toward mastering real time data, manual processes are becoming obsolete. Manual data entry is prone to human error, which can lead to misclassification and security leaks.
Data Entry Automation Software and artificial intelligence in business are revolutionizing this space. By using automated browser data entry and website data entry automation, companies can classify thousands of documents per second with high accuracy.
For small businesses, automation for small businesses—such as automating excel spreadsheets—can provide a “poor man’s” classification system that saves hours of labor. Furthermore, automated crm data entry ensures that customer data is tagged the moment it enters the sales funnel, supporting B2B lead generation while maintaining privacy.
Data Classification and Modern Marketing

Interestingly, data classification plays a huge role in digital marketing analytics. By categorizing customer behavior data, marketers can perform customer journey mapping more effectively. Whether it is luxury brand marketing or CPG brand marketing, knowing which data is “Public” (for brand awareness) and which is “Confidential” (customer PII) is essential for brand safety in digital marketing.
Using marketing analytics tools and advanced web analytics, businesses can segment their audiences without violating privacy laws. This synergy between security and marketing ensures a strong brand perception in marketing and builds brand loyalty.
To provide a truly comprehensive guide, we need to explore how data classification interacts with modern technology stacks, the human element of security, and the specific regulatory landscapes that define today’s digital economy.
The Role of Data Classification in the Modern Tech Stack
As organizations migrate to hybrid environments, data classification acts as the glue between on-premises security and cloud flexibility. Integrating classification with SaaS development services ensures that data remains protected even when it leaves the corporate network.
Integration with Data Loss Prevention (DLP)
DLP tools rely on classification tags to function. For example, if a document is tagged as “Restricted,” the DLP system will automatically block it from being uploaded to a personal cloud storage account or sent via outbound email marketing channels. This creates an automated safety net that prevents human error from becoming a data breach.
Enhancing CRM and ERP Systems
Modern businesses use Hubspot data entry and automated data entry xero to manage customer relationships and finances. By classifying data at the point of entry, these systems can automatically apply “Confidential” tags to customer PII (Personally Identifiable Information). This ensures that only authorized personnel can view sensitive financial reports, maintaining brand safety in digital marketing and internal trust.
Data Classification and Regulatory Compliance
Compliance is often the primary driver for data classification. Different regulations require different levels of “Data Discovery” and protection.
- GDPR (General Data Protection Regulation): Requires identifying any data related to EU citizens. Classification helps by marking this as “Regulated Data.”
- HIPAA (Health Insurance Portability and Accountability Act): Specifically targets “Protected Health Information” (PHI). Classification ensures this data is encrypted and audit-trailed.
- PCI DSS: Focuses on credit card information. Using manual invoice data entry with classification labels helps identify which systems need to be PCI-compliant.
By utilizing marketing analytics tools and advanced web analytics, companies can ensure they are only collecting the data they are legally allowed to store, thus avoiding massive regulatory fines.
The Human Element: Training and Brand Voice

Technology is only half the battle. User-defined classification requires employees to make split-second decisions about the sensitivity of their work. This is where brand voice strategy and internal communications come into play.
Building a Security Culture
Organizations should use webinars for education to train staff on classification levels. A complete guide to webinar monetization might focus on external profit, but internal webinars focus on “Informational Asset Protection.” When employees understand that “Restricted” data is the “Secret Sauce” of the company’s brand positioning, they are more likely to treat it with care.
Improving Data Integrity
Using textual data entry standards helps maintain consistency. When every department uses the same naming conventions and classification tags, data discovery becomes a seamless process rather than a digital scavenger hunt.
Advanced Strategies: AI and Machine Learning
The future of data classification lies in artificial intelligence in business. Manual classification cannot keep up with the petabytes of data generated daily.
AI-Driven Trend Forecasting
AI can predict which data will become sensitive over time. For instance, in luxury brand marketing, a customer’s purchasing habits might be “Internal” today but become “Confidential” as they move through a specific customer journey mapping phase. Ai driven trend marketing allows systems to adjust classification levels dynamically based on the perceived risk and value of the information.
Automated Excel and Browser Tasks
For smaller operations, mastering automation in excel data entry and automate browser data entry can act as a bridge. These scripts can scan for keywords (like “Invoice” or “SSN”) and automatically apply formatting or tags that signal the data’s importance to the user.
Key Performance Indicators (KPIs) for Data Classification
To measure the success of your program, track the following brand equity KPIs and security metrics:
| Metric | Description | Goal |
| Discovery Rate | Percentage of total data successfully classified. | > 95% |
| False Positive Rate | How often “Public” data is incorrectly tagged as “Restricted.” | < 2% |
| User Override Frequency | How often employees manually change an AI-assigned tag. | Low |
| Storage Cost Reduction | Savings achieved by moving non-critical data to “Cold” storage. | 20-30% |
Conclusion
Implementing a robust data classification framework is no longer optional in the digital age. It is a fundamental business practice that protects your most valuable informative assets while driving efficiency and compliance. By combining clear policies with artificial intelligence in business, your organization can turn data from a liability into a powerful strategic advantage.
FAQs
1. What is the difference between data classification and data indexing?
Data classification categorizes data based on its sensitivity and risk for security purposes. Indexing, often used in textual data entry, organizes data for fast search and retrieval based on keywords.
2. Can small businesses benefit from data classification?
Absolutely. Using automation for small businesses to classify financial records or client lists helps prevent data loss and prepares the business for growth and future audits.
3. How does AI improve the classification process?
Artificial intelligence in business allows for “Content-Based Classification.” AI can read the “intent” of a document, distinguishing between a generic contract and one containing high-value trade secrets.
4. Is data classification required by law?
While the term might not be in every law, regulations like GDPR and HIPAA essentially require it by mandating specific protections for “Personal Data” or “Protected Health Information.”
5. How often should data be re-classified?
Data sensitivity changes. A product launch plan is “Restricted” before the launch but may become “Public” after. Periodic audits are a best practice.
6. What are the common challenges in classification?
The biggest challenges include “Data Overload” (too much information), manual errors in manual invoice data entry, and lack of employee training.
7. How does it help with storage costs?
By identifying “Public” or “Internal” data that is no longer needed, you can move it to cheaper, long-term “cold” storage, or delete it, saving on high-performance server space.
8. What tools are best for automation?
Tools like Data Entry Automation Software and Automated CRM data entry systems are excellent. For Excel users, mastering automation in excel data entry using macros can be a great start.
9. Can classification help with B2B Lead Generation?
Yes. By classifying leads based on their brand personality or brand positioning, sales teams can tailor their outreach while ensuring the data remains secure within their CRM.
10. Where should I start if I have no system in place?
Start with a “Data Discovery” phase. Use automated browser data entry tools or discovery software to see where your files are stored and identify your most sensitive 10% of data.
")







{kind=link}